Automating the Process of Dictionary Creation
Building upon the material covered in LEX2: Mastering ELEXIS Corpus Tools for Lexicographic Purposes and Lexonomy: Mastering the ELEXIS Dictionary Writing System, this course will focus specifically on the changes in dictionary production after 2000 and the increasing importance of automation and post-editing in lexicography. The course will focus on the ELEXIS One-Click Dictionary as a corpus- based dictionary-drafting tool and the way Lexonomy DWS can be used to post-edit content which has been automatically pulled from ELEXIS Corpus Tools.
Learning Outcomes
Upon completion of this course, students will be able to
- appreciate/understand the changes in the process of creating dictionaries in the past few decades
- use the OnceClick Dictionary functionality in Sketch Engine
- post-edit automatically pulled content in Lexonomy
Prerequisites
For a deeper understanding of the corpus analysis tools and dictionary editing tools (Lexonomy) mentioned in this chapter, the student is expected to refer to LEX2: Mastering ELEXIS Corpus Tools for Lexicographic Purposes and Lexonomy: Mastering the ELEXIS Dictionary Writing System courses here on DARIAH-Campus.
TOC
- The rise of post editing in lexicography
-
- effectivity and practical considerations
- streamlined postediting by data type
- management implications of the post editing process
- Dictionary entry components and their automatic extraction from corpora
-
- headword list editing - selecting the right entries
- data from a corpus without text types
- data from a corpus with text types
- word sense disambiguation
- Automatic drafting of dictionary entries
-
- OneClick Dictionary - push and pull
- Post-editing in a dictionary writing system
-
- Lexonomy
The rise of post editing in lexicography
Automating the creation of dictionary is not a new concept as presented in Rundell, M. and Kilgarriff, A. 2011.
The relationship between dictionaries and computers goes back around 50 years. But for most of that period, technology’s main contributions were to facilitate the capture and manipulation of dictionary text, and to provide lexicographers with greatly improved linguistic evidence. Working with computers and corpora had become routine by the mid-1990s, but there was no real sense of lexicography being automated. In this article we review developments in the period since 1997, showing how some of the key lexicographic tasks are beginning to be transferred, to a significant degree, from humans to machines. A recurrent theme is that automation not only saves effort but often leads to a more reliable and systematic description of a language. We close by speculating on how this process will develop in years to come.
Rundell, M. and Kilgarriff, A. 2011. ‘Automating the creation of dictionaries: where will it all end?’, in A Taste for Corpora. A tribute to Professor Sylviane Granger. Meunier F., De Cock S., Gilquin G. and Paquot M. (eds), Benjamins. 257-281.
The key concept in automating the process is not that computers should be able to produce the final version of a dictionary completely automatically. This seems rather unrealistic. The automation refers to using computers to pre-generating the content of the dictionary automatically. Such a dictionary draft will then be post edited by human editors.
The idea of post editing is still quite revolutionary in lexicography, however, it is already well established in translation where translators frequently have the text translated using machine translation and they only post-edit it. This proved much more effective than translating everything from scratch. The same applies to lexicography.
Effectivity and practical considerations
Automatically generated drafts make the dictionary financially more viable, faster to produce and allow including more information. Automation also ensures larger coverage of linguistic features because the draft is normally configured to include more information than necessary. This is because it is easier to remove information than to add it and, therefore, it is less likely that some information gets omitted from the dictionary. This is only true if a corpus of an adequate size is used to ensure that even rare phenomena appear in the data frequently enough to be detected. In practice, a large multi-billion-word corpus is required. Corpora of only millions or dozens of millions of words are totally unsuitable for creating a general language dictionary. Smaller corpora are only justifiable for the creation of specialized dictionaries.
Streamlined postediting by data type
Automation of dictionary creation naturally brings about quite a different workflow compared to the workflow of lexicographers in the past. Traditionally, dictionaries were compiled sequentially starting with the first letter and the first entry and after each entry was finished, the lexicographer moved on to another entry. In practice, the work was not completely sequential, entries were often grouped by types or domains and different lexicographers were responsible for certain entry types or topics. But they still worked using the entry-by-entry system.
Using automation does not generate data entry-by-entry. Instead, each step generates one type of data for all entries in the dictionary. For example, one step will generate example sentences for all entries, another step will generate inflected forms for all entries and so on. This naturally leads to the change in workflow. Rather than ensuring that an entry is complete before moving on to the next one, it is far more effective to have editors validate and edit a certain data type for all entries. Since such a task is fairly clearly defined, it is easier to train the editor in just one task. This even allows the task to be completed by a non-lexicographer or non-linguist who was trained in only this clearly defined task.
This screenshot shows one of the Lexonomy interfaces used for editing a Ukrainian dictionary. This one is intended for the editors to clean the headword list and identify items which do not qualify as headwords. The diagram reminds them of the required decision-taking process.
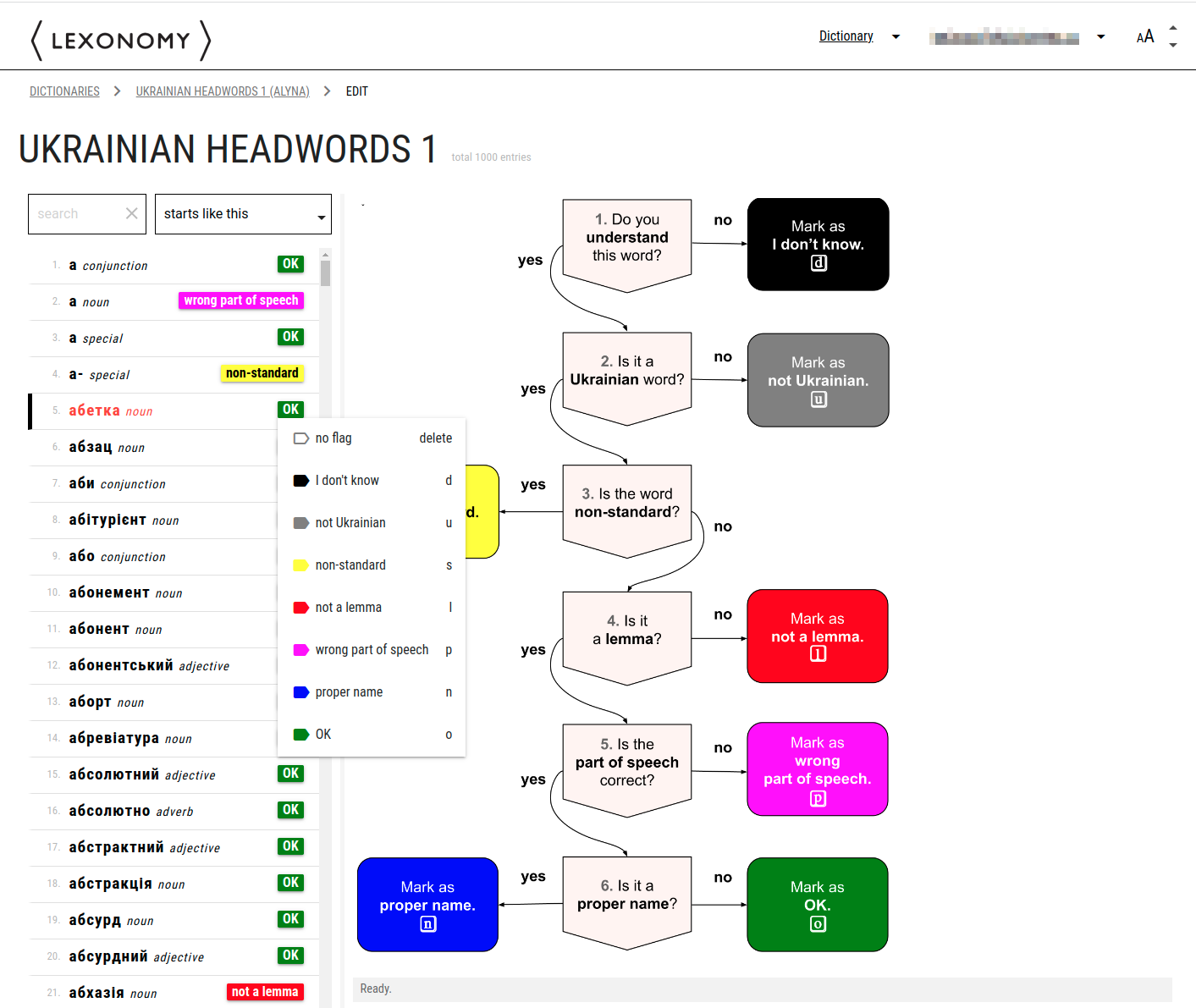
Each component of a dictionary entry will have its own interface displaying information and containing relevant controls depending on the type of data and the expected actions that the editor needs to take.
Management implications of the post editing process
The new workflow of editing by data type brings about new management challenges. When the dictionary draft editing process is well planned, it makes it possible to use lexicographers as trainers and supervisors while the actual editing can be done by non-lexicographers or by non-linguists. With post editing by data types, it is possible to train a non-expert fairly quickly in performing only one clearly defined task well. This is in contrast to the entry-by-entry editing when the lexicographer needed an in-depth training in many aspects of lexicography to be able to design the complete dictionary entry.
Editing by data type is especially effective with less resourced languages or languages with a low number of speakers where it might be completely impossible to find a traditionally trained lexicographer with the knowledge of the language.
The management challenges involve:
- training and people management
- division and merging of data
- entry internal cohesion
Training and people management
Postediting by data types means that during one editing task, editors only need to focus on one clearly defined activity. For example: checking the correct assignment of the part of speech. Training the editors for such a clearly defined task is much faster and easier than training editors to edit the whole entry. The task can often be performed by speakers of the language without a background in linguistics or lexicography. Different parts of dictionary entries can be edited by editors of different abilities: translations may require speakers of both languages, other parts only require a speaker of one language; some tasks may require speakers with a basic linguistic awareness (e.g. language teachers), other tasks may not require it at all.
The clearly defined task makes it possible to prepare short checklists or guidelines that the editors can refer to during the actual work. This increases the consistency between them.
Editors will typically work at different pace and while some of them have finished their batch, others are still working on theirs. This should be anticipated and new batches should be ready when the previous ones are completed to make the best use of editors’ time.
Division and merging of data
Typically, a dictionary will have thousands of entries. It is not realistic for a single person to perform the post editing of a certain data type on all the entries. It is inevitable that the whole dictionary has to be divided into smaller batches of several hundred entries. The batches need to be distributed to different editors, collected when finished and then merged onto one database again.
This assumes that the publisher is technically ready to undertake such a task successfully. Skilled IT professionals able to seamlessly manipulate large amounts of text data are a must.
Entry internal cohesion
Different parts of the same entry will be typically edited by different editors. It is therefore important to ensure that the entry as a whole does not contain fragmental or even contradictory information. For instance, the example sentences should illustrate the main syntactic and semantic features of the headword. This should be taken into account when pregenrating the dictionary draft. It is, therefore, preferable that the example sentences are not just random example sentences but are sentences containing the most typical collocations or multiword expressions that the headword forms.
Dictionary entry components and their automatic extraction from corpora
Headword list editing
The work on a dictionary starts by creating a headword list. This typically involves the extraction of a frequency list of lemmas from a lemmatized corpus. The postediting then involves cleaning the wordlist to only preserve entries which are:
- legitimate words in the language of the dictionary
- correct lemmas
- lemmas spelt correctly
- lemmas with the correct part of speech
The creation of a dictionary from a corpus assumes that the corpus is lemmatized and tagged for parts of speech. A corpus that is not lemmatized has very little value for this task. The absence of part-of-speech tags can be tolerated in certain situations but, generally speaking, is rarely acceptable because the corpus software typically uses the information to retrieve relevant lexicographic data.
Although text types are a major benefit, even a lemmatized and tagged corpus without text types is a good source of lexicographic data. By text types we refer to metadata assigned to longer stretches of texts such as sentences, paragraphs or documents. Text types may include information such as publication date, source name, publisher, author name, author age, register, type of writing, language variety, and many others.
Data from a corpus without text types
A corpus that is lemmatized and tagged for parts of speech but without text types can be used to generate these lexicographic data automatically:
- headword list
- part of speech labels
- frequency information
- inflected forms of the headword
- collocations
- multiword expressions containing the headword
- thesaurus
- examples of use
- word senses
- derived words
- typical structures in which the headword is used
Data from a corpus with text types
A corpus with text types can be used to generate additional information which depends on the available metadata. Such metadata can be used to generate entry labels or usage statistics. The table below gives a non-exhaustive overview of the types of metadata and the lexicographic information that can be extracted from them.
| text type (metadata) | lexicographic information |
|---|---|
| geographical location | regional language variants |
| domain, topic, subject | subject specific words/senses |
| mode | labels: spoken, written |
| formality | labels: formal, informal, colloquial, slang |
| genre | labels: academic, creative writing, news, informative, promotional, instructional… |
There are many other types of metadata that can be included in the corpus depending on the aim of its use. They may include:
age of the author
- education of the author
- mother tongue of the author
- native vs. non-native speaker
- classification of texts into categories such as news article, novel, poem, transactional letter, email, blog post, instant messaging, reference book, autobiography…
and many others.
These aspects should be considered at the planning stage and taken into account during the corpus building process. Generally speaking, it is easier to collect and add metadata while the corpus is being built rather than add them after the corpus is complete.
Word sense disambiguation
While it is not yet possible for an algorithm to reliably identify word senses, it is already possible to suggest word sense candidates automatically. This is typically done by grouping similar collocates of the headword. As a rule of thumb, it is always better to set up the system so that it produces a finer division of senses. It is the job of the post editor to edit, merge or completely remove the unwanted senses. Working from more candidates to fewer final senses ensures that no sense remain undetected.
Automatic drafting of dictionary entries
The automatic dictionary drafting process should leverage the relevant functionality of the corpus management system to produce the required data and process them into a format that can be uploaded into a dictionary writing system, or DWS, where editors will carry out the post-editing stage.
Dictionary drafting module
A dictionary drafting module designed to convert data produced by a corpus system into data format compliant with input format of a DWS was produced by the ELEXIS project.
OneClick Dictionary
The dictionary drafting module is available at the following link https://github.com/elexis-eu/ocd In addition, the module is integrated into the Sketch Engine interface where it acts as a link between Sketch Engine and the Lexonomy dictionary writing system. More details about OneClick Dictionary can also be found on
https://elex.is/wp-content/uploads/2020/02/ELEXIS_D4_2_Dictionary_Drafting_Module.pdf
OneClick Dictionary supports two modes of use - push and pull.
Push
The push mode is used when generating the primary draft of the dictionary. It leverages the relevant functionality of Sketch Engine, collects the required data, processes them into the Lexonomy data format and pushes the data into Lexonomy.
Pull
The pull mode is primarily intended to be used during the post editing process. When an editor requires additional data to be extracted from the corpus, for example when more example sentences should be found, the editor activates this function in Lexonomy and it will use the functionality in Sketch Engine to find more examples and pulls them from Sketch Engine to Lexonomy.
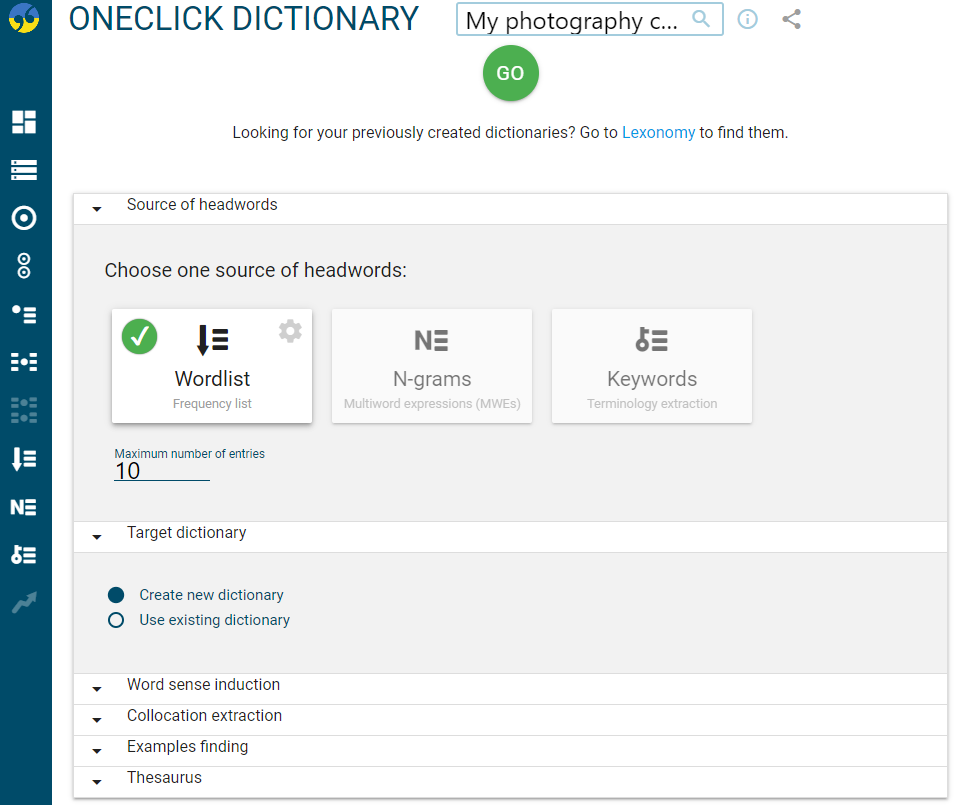
The following screenshot shows the settings of the OneClick Dictionary interface used in the Push mode to generate 10 dictionary entries from a corpus about digital photography.
Post-editing in a dictionary writing system
The dictionary draft is edited in a dictionary writing system (DWS). An example of a DWS is Lexonomy which is an open-source DWS.
Lexonomy
Lexonomy main installation is free for use for academic purposes on www.lexonomy.eu
It can also be downloaded here https://github.com/elexis-eu/lexonomy
There is a separate course of using Lexonomy: